Get started with getML¶
In this example, you will learn about the basic concepts of getML. You will tackle a simple problem using the Python API in order to gain a technical understanding of the benefits of getML. More specifically, you will learn how to do the following:
The guide is applicable to both the enterprise and the community editions of getML. The highlights of the two are mentioned under community vs enterprise edition section below.
You have not installed getML on your machine yet? Before you get started, head over to the installation instructions: for the enterprise edition or for the community edition.
Introduction¶
Automated machine learning (AutoML) has attracted a great deal of attention in recent years. The goal is to simplify the application of traditional machine learning methods to real world business problems by automating key steps of a data science project, such as feature extraction, model selection, and hyperparameter optimization. With AutoML, data scientists are able to develop and compare dozens of models, gain insights, generate predictions, and solve more business problems in less time.
While it is often claimed that AutoML covers the complete workflow of a data science project - from the raw data set to the deployable machine learning models - current solutions have one major drawback: They cannot handle real world business data. This data typically comes in the form relational data. The relevant information is scattered over a multitude of tables that are related via so-called join keys. In order to start an AutoML pipeline, a flat feature table has to be created from the raw relational data by hand. This step is called feature engineering and is a tedious and error-prone process that accounts for up to 90% of the time in a data science project.
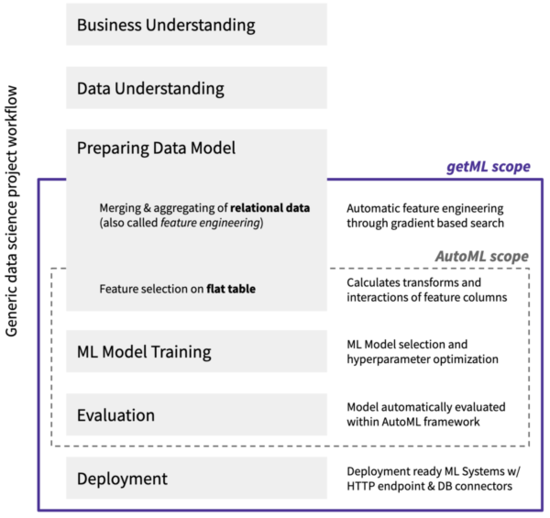
getML adds automated feature engineering on relational data and time series to AutoML. The getML algorithms, Multirel and Relboost, find the right aggregations and subconditions needed to construct meaningful features from the raw relational data. This is done by performing a sophisticated, gradient-boosting-based heuristic. In doing so, getML brings the vision of end-to-end automation of machine learning within reach for the first time. Note that getML also includes automated model deployment via a HTTP endpoint or database connectors. This topic is covered in other material.
All functionality of getML is implemented in the so-called getML engine. It is written in C++ to achieve the highest performance and efficiency possible and is responsible for all the heavy lifting. The getML Python API acts as a bridge to communicate with engine. In addition, the getML monitor (available in enterprise edition) provides a Go-based graphical user interface to ease working with getML and significantly accelerate your workflow.
In this article, we start with a brief glimpse of different toolsets offered by getML community and enterprise editions. Later on, you will learn the basic steps and commands to tackle your data science projects using the Python API. For illustration purpose we will also touch how an example data set like the one used here would have been dealt with using classical data science tools. In contrast, we will show how the most tedious part of a data science project - merging and aggregating a relation data set - is automated using getML. At the end of this tutorial you are ready to tackle your own use cases with getML or dive deeper into our software using a variety of follow-up material.
Community vs enterprise edition¶
Before you start the tutorial, here are the highlights of the open-source getML community edition and full-featured getML enterprise edition:
Community edition |
Enterprise edition |
|
|---|---|---|
License |
Elastic Licence v2 |
Proprietary |
Platform |
Linux & Docker |
Also macOS |
Preprocessors |
EmailDomain, Imputation, Seasonal, Substring, TextFieldSplitter |
Also Mapping |
Feature learners |
FastProp |
Also Multirel, Relboost, RelMT |
Predictors |
LinearRegression, LogisticRegression, XGBoost |
Same |
Productionization |
Transpilation to human-readable SQL |
Also transpilation to SQLite, Spark SQL, SAP HANA, BigQuery, SnowflakeSQL, TSQL. Built-in HTTP Endpoints. |
Hyperparameter optimization |
RandomSearch, LatinHypercube, GaussianOptimization, Customized tuning routines |
Same |
Database connectors |
SQLite, MySQL, MariaDB, PostgreSQL |
Also Greenplum, ODBC, SAP HANA, BigQuery, Snowflake |
Other data sources |
CSV, Parquet, Pandas, Arrow, Pyspark, JSON |
Also S3 |
Other functionalities |
Memory mapping |
Also web frontend |
Starting a new project¶
After you’ve successfully installed getML (enterprise or community), you can begin by executing the following in a jupyter-notebook:
>>> import getml
>>> print(f"getML API version: {getml.__version__}\n")
getML API version: 1.3.0
>>> getml.engine.launch()
Launched the getML engine. The log output will be stored in
/home/xxxxx/.getML/logs/xxxxxxxxxxxxxx.log.
This will import the getML Python API, launch the engine and the monitor.
Alternatively, you can also launch the getML engine and the monitor as follows:
– On Mac, execute
getml-cliinside a terminal or double-click the application icon.– On Windows/docker, execute
run.shin Git Bash.– On Linux, execute
getMLinside a terminal.
Now, inside Python, execute import getml to import the API.
The getML Monitor, available in the enterprise edition, is the frontend to the engine. It should open automatically by launching the engine. In case it does not, visit http://localhost:1709/ to open it. From now on, the entire analysis is run from Python. We will cover the getML monitor in a later tutorial but feel free to check what is going on while following this guide.
The entry-point for your project is the project module. From here,
you can start projects and control running projects. Further, you have access to
all project specific entities, and you can export a project as a .getml bundle
to disk or load a .getml bundle from disk. To see the running projects, you
can execute:
>>> getml.project
Cannot reach the getML engine. Please make sure you have set a project.
To set: `getml.engine.set_project`
Available projects:
This message tells us, that we have no running engine instance because we have
not set a project. So, we follow the advice and create a new project. All data
sets and models belonging to a project will be stored in ~/.getML/projects.
>>> getml.engine.set_project("getting_started")
Connected to project 'getting_started'
http://localhost:1709/#/listprojects/getting_started/
Now, when you check the current projects:
>>> getml.project
Current project:
getting_started
Data set¶
The data set used in this tutorial consists of 2 tables. The so-called population table represents the entities we want to make a prediction about in the analysis. The peripheral table contains additional information and is related to the population table via a join key. Such a data set could appear, for example, in a customer churn analysis where each row in the population table represents a customer and each row in the peripheral table represents a transaction. It could also be part of a predictive maintenance campaign where each row in the population table corresponds to a particular machine in a production line and each row in the peripheral table to a measurement from a certain sensor.
In this guide, however, we do not assume any particular use case. After all, getML is applicable to a wide range of problems from different domains. Use cases from specific fields are covered in other articles.
>>> population_table, peripheral_table = getml.datasets.make_numerical(
... n_rows_population=500,
... n_rows_peripheral=100000,
... random_state=1709
... )
>>> getml.project.data_frames
name rows columns memory usage
0 numerical_peripheral_1709 100000 3 2.00 MB
1 numerical_population_1709 500 4 0.01 MB
>>> population_table
Name time_stamp join_key targets column_01
Role time_stamp join_key target numerical
Units time stamp, comparison only
0 1970-01-01 00:00:00.470834 0 101 -0.6295
1 1970-01-01 00:00:00.899782 1 88 -0.9622
2 1970-01-01 00:00:00.085734 2 17 0.7326
3 1970-01-01 00:00:00.365223 3 74 -0.4627
4 1970-01-01 00:00:00.442957 4 96 -0.8374
... ... ... ...
495 1970-01-01 00:00:00.945288 495 93 0.4998
496 1970-01-01 00:00:00.518100 496 101 -0.4657
497 1970-01-01 00:00:00.312872 497 59 0.9932
498 1970-01-01 00:00:00.973845 498 92 0.1197
499 1970-01-01 00:00:00.688690 499 101 -0.1274
500 rows x 4 columns
memory usage: 0.01 MB
name: numerical_population_1709
type: getml.data.DataFrame
url: http://localhost:1709/#/getdataframe/getting_started/numerical_population_1709/
The population table contains 4 columns. The column called column_01
contains a random numerical value. The next column, targets, is the
one we want to predict in the analysis. To this end, we also need to use
the information from the peripheral table.
The relationship between the population and peripheral table is
established using the join_key and time_stamp columns: Join keys
are used to connect one or more rows from one table with one or more
rows from the other table. Time stamps are used to limit these joins by
enforcing causality and thus ensuring that no data from the future is
used during the training.
In the peripheral table, columns_01 also contains a random numerical
value. The population table and the peripheral table have a one-to-many
relationship via join_key. This means that one row in the population
table is associated to many rows in the peripheral table. In order to
use the information from the peripheral table, we need to merge the many
rows corresponding to one entry in the population table into so-called
features. This is done using certain aggregations.
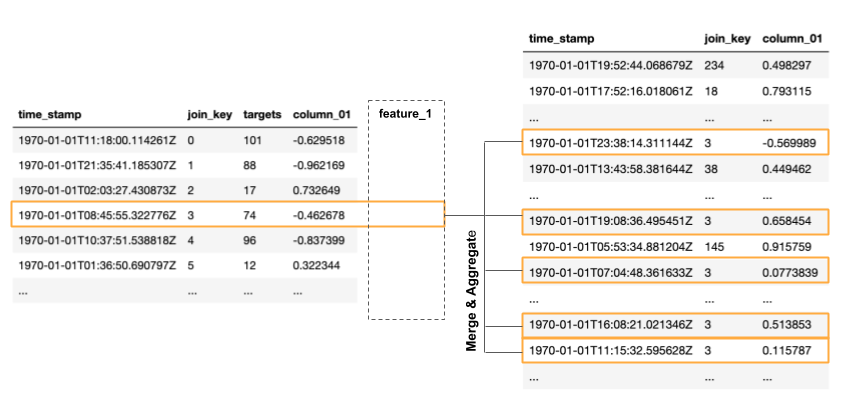
For example, such an aggregation could be the sum of all values in
column_01. We could also apply a subcondition, like taking only
values into account that fall into a certain time range with respect to
the entry in the population table. In SQL code such a feature would look
like this:
SELECT COUNT( * )
FROM POPULATION t1
LEFT JOIN PERIPHERAL t2
ON t1.join_key = t2.join_key
WHERE (
( t1.time_stamp - t2.time_stamp <= TIME_WINDOW )
) AND t2.time_stamp <= t1.time_stamp
GROUP BY t1.join_key,
t1.time_stamp;
Unfortunately, neither the right aggregation nor the right subconditions
are clear a priori. The feature that allows us to predict the target
best could very well be e.g. the average of all values in column_01
that fall below a certain threshold, or something completely different.
If you were to tackle this problem with classical machine learning
tools, you would have to write many SQL features by hand and find the
best ones in a trial-and-error-like fashion. At best, you could apply
some domain knowledge that guides you towards the right direction. This
approach, however, bears two major disadvantages that prevent you from
finding the best-performing features.
You might not have sufficient domain knowledge.
You might not have sufficient resources for such a time-consuming, tedious, and error-prone process.
This is where getML comes in. It finds the correct features for you - automatically. You do not need to manually merge and aggregate tables in order to get started with a data science project. In addition, getML uses the derived features in a classical AutoML setting to easily make predictions with established and well-performing algorithms. This means getML provides an end-to-end solution starting from the relational data to a trained ML-model. How this is done via the getML Python API is demonstrated in the following.
Defining the data model¶
Most machine learning problems on relational data can be expressed as
a simple star schema.
This example is no exception, so we will use the predefined
StarSchema class.
>>> split = getml.data.split.random(train=0.8, test=0.2)
>>> star_schema = getml.data.StarSchema(
... population=population_table, alias="population", split=split)
>>> star_schema.join(peripheral_table,
... alias="peripheral",
... on="join_key",
... time_stamps="time_stamp",
... )
Building a pipeline¶
Now we can define the feature learner. Additionally, you can alter some hyperparameters like the number of features you want to train or the list of aggregations to select from when building features.
>>> fastprop = getml.feature_learning.FastProp(
... num_features=10,
... aggregation=[
... getml.feature_learning.aggregations.Count,
... getml.feature_learning.aggregations.Sum
... ],
... )
getML bundles the sequential operations of a data science project
(Preprocessing, Feature engineering and Predicting) into
Pipeline objects. In addition to the
Placeholders representing the
DataFrames you also have to provide a feature learner
(from getml.feature_learning) and a predictor (from
getml.predictors).
>>> pipe = getml.pipeline.Pipeline(
... data_model=star_schema.data_model,
... feature_learners=[fastprop],
... predictors=[getml.predictors.LinearRegression()],
... )
We have chosen a narrow search field in aggregation space by only
letting FastProp use Count and Sum. For the sake of
demonstration, we use a simple LinearRegression and construct only
10 different features. In real world projects you would construct at
least ten times this number and get results significantly better than
what we will achieve here.
Working with a pipeline¶
Now, that we have defined a Pipeline, we can let getML
do the heavy lifting of your typical data science project. With a well-defined
Pipeline, you can, i.a.:
fit()the pipeline, to learn the logic behind your features (also referred to as training);score()the pipeline to evaluate its performance on unseen data;transform()the pipeline and materialize the learned logic into concrete (numerical) features;deploy()the pipeline to an http endpoint.
Training¶
When fitting the model, we pass the handlers to the actual data residing
in the getML engine – the DataFrames.
>>> pipe.fit(star_schema.train)
Checking data model...
Staging...
[========================================] 100%
Checking...
[========================================] 100%
OK.
Staging...
[========================================] 100%
FastProp: Training 5 features...
[========================================] 100%
FastProp: Building features...
[========================================] 100%
LinearRegression: Training as predictor...
[========================================] 100%
Trained pipeline.
Time taken: 0h:0m:0.049154
Pipeline(data_model='population',
feature_learners=['FastProp'],
feature_selectors=[],
include_categorical=False,
loss_function='SquareLoss',
peripheral=['peripheral'],
predictors=['LinearRegression'],
preprocessors=[],
share_selected_features=0.5,
tags=['container-s0mKB6'])
url: http://localhost:1709/#/getpipeline/getting_started/MXzNDT/0/
That’s it. The features learned by
FastProp as well as the
LinearRegression in are now trained on our data set.
Scoring¶
We can also score our algorithms on the test set.
>>> pipe.score(star_schema.test)
Staging...
[========================================] 100%
Preprocessing...
[========================================] 100%
FastProp: Building features...
[========================================] 100%
date time set used target mae rmse rsquared
0 2022-09-02 10:14:12 train targets 3.3721 4.1891 0.9853
1 2022-09-02 10:14:12 test targets 3.7548 4.7093 0.981
Our model is able to predict the target variable in the newly generated data set
pretty accurately. Though, the enterprise feature learner
Multirel performs even better here with R2
of 0.9995 and MAE and RMSE of 0.07079 and 0.1638 respectively.
Making predictions¶
Let’s simulate the arrival of unseen data and generate another population table. Since
the data model is already stored in the pipeline, we do not need to recreate it
and can just use a Container instead of a
StarSchema.
>>> population_table_unseen, peripheral_table_unseen = getml.datasets.make_numerical(
... n_rows_population=200,
... n_rows_peripheral=8000,
... random_state=1711,
... )
>>> container_unseen = getml.data.Container(population_table_unseen)
>>> container_unseen.add(peripheral=peripheral_table_unseen)
>>> yhat = pipe.predict(container_unseen.full)
Staging...
[========================================] 100%
Preprocessing...
[========================================] 100%
FastProp: Building features...
[========================================] 100%
>>> print(yhat[:10])
[[ 4.16876676]
[17.32933 ]
[26.62467516]
[-5.30655759]
[27.4984785 ]
[21.48631811]
[18.16896219]
[ 5.2784719 ]
[20.5992354 ]
[26.20538556]]
Extracting features¶
Of course you can also transform a specific data set into the corresponding features in order to insert them into another machine learning algorithm.
>>> features = pipe.transform(container_unseen.full)
>>> print(features)
[[-7.14232213e-01 2.39745475e-01 2.62855261e-01 1.28462060e-02
5.00000000e+00 -3.18568319e-01]
[-1.17601634e-01 3.42472663e+00 3.61423201e+00 3.24305583e-02
1.40000000e+01 3.94656676e-01]
[-2.48645436e+00 1.27495266e+01 1.33228011e+01 1.99520872e-02
3.60000000e+01 1.24700392e-01]
...
[ 9.55124379e-01 9.16437833e-01 9.40897830e-01 2.73040074e-02
8.00000000e+00 -7.49963688e-01]
[-3.56023429e+00 3.37346772e+00 2.11562428e+00 2.53698895e-02
1.50000000e+01 -7.27880243e-01]
[ 2.72804029e-02 2.87302783e-02 5.36035230e-02 2.77103542e-02
2.00000000e+00 -3.53700424e-01]]
If you want to see a SQL transpilation of a feature’s logic, you can do so by
clicking on the feature in the monitor (enterprise edition only) or by
inspecting the sql attribute on a feature. A Pipelines features are hold by the Features container. For
example, to inspect the sql code of one of the features:
>>> pipe.features[1].sql
That should return something like this:
DROP TABLE IF EXISTS "FEATURE_1_5";
CREATE TABLE "FEATURE_1_5" AS
SELECT COUNT( * ) AS "feature_1_5",
t1.rowid AS rownum
FROM "POPULATION__STAGING_TABLE_1" t1
INNER JOIN "PERIPHERAL__STAGING_TABLE_2" t2
ON t1."join_key" = t2."join_key"
WHERE t2."time_stamp" <= t1."time_stamp"
GROUP BY t1.rowid;
This very much resembles the ad hoc definition we tried in the beginning. The
correct aggregation to use on this data set is Count. getML extracted this
definition completely autonomously.
Next steps¶
This guide has shown you the very basics of getML. Starting with raw data you have completed a full project including feature engineering and linear regression using an automated end-to-end pipeline. The most tedious part of this process - finding the right aggregations and subconditions to construct a feature table from the relational data model - was also included in this pipeline.
But there’s more! Related articles show application of getML on real world data sets.
Also, don’t hesitate to contact us with your feedback.