Data model¶
Defining the data model is a crucial step before training one of
getML’s Pipeline s. You typically deal with this
step after having imported your data and
specified the roles of each columns.
When working with getML, the raw data usually comes in the form of relational data. That means the information relevant for a prediction is spread over several tables. The data model is the definition of the relationships between all of them.
Most relational machine learning problems can be represented in the form
of a star schema, in which case you can use the StarSchema
abstraction. If your data set is a time series, you can use the
TimeSeries abstraction.
Tables¶
When defining the data model, we distinguish between a population table and
one or more peripheral tables. In the context of this tutorial, we will
use the term “table” as a catch-all for DataFrame s and
View s.
The population table¶
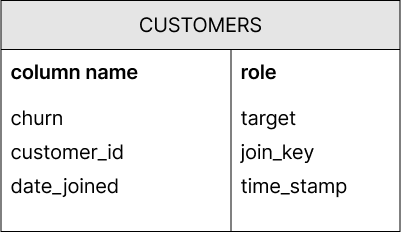
The population table is the main table of the analysis. It defines the statistical population of your machine learning problem (hence the name) and contains the target variable(s). A target variable is the variable which is the variable we want to predict. Furthermore, the table usually also contains one or more columns with the role join_key. These are keys used to establish a relationship – also called joins – with one or more peripheral tables.
The following example contains the population table of a customer churn
analysis. The target variable is churn – whether a person
stops using the services and products of a company. It contains the
information whether or not a given customer has churned after a certain
reference date. The join key customer_id is used to establish
relations with a peripheral
table. Additionally, the date the
customer joined our fictional company is contained in column
date_joined, which we have assigned the role
time_stamp.
Peripheral tables¶
Peripheral tables contain additional information relevant for the prediction of the target variable in the population table. Each of them is related to the latter (or another peripheral table, refer to the snowflake schema) via a join_key.
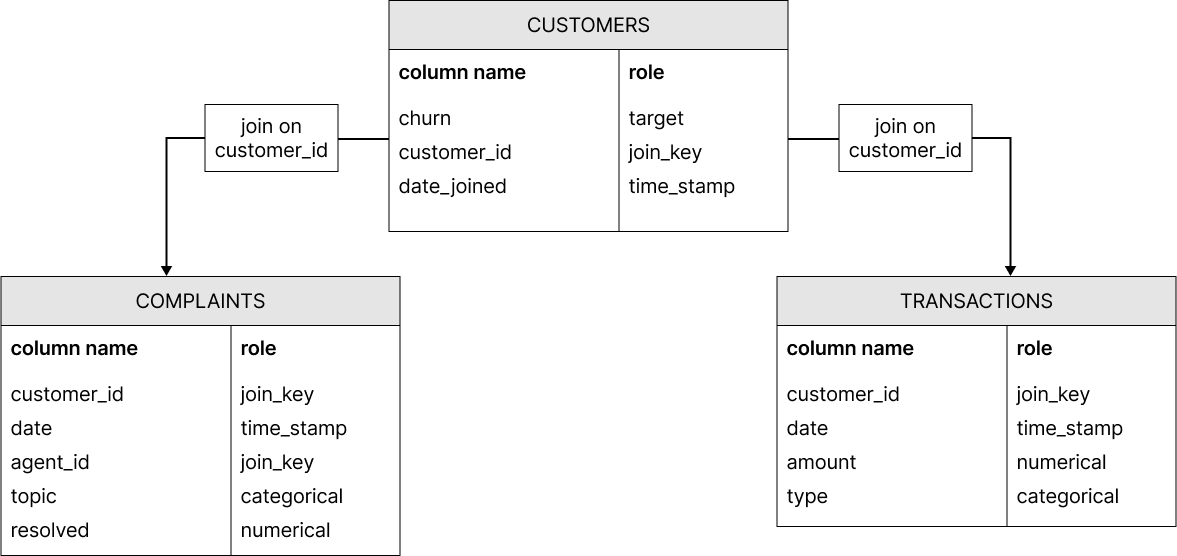
The following pictures contain two peripheral tables that could be used for our customer churn analysis from the example above. One represents complaints a certain customer made with a certain agent and the other the transactions the customer made using her account.

Placeholders¶
In getML, Placeholder s are used to construct the
DataModel. They are abstract representations of
DataFrame s or View s and
the relationships among each other, but do not
contain any data themselves.
The idea behind the placeholder concept is that they allow
constructing an abstract data model without any reference to an actual
data set. This data model serves as input for the Pipeline.
Later on, the feature_learning
algorithms can be trained and applied on any data set that follows this
data model.
More information
on how to construct placeholders and build a data model can be found in
the API documentation for Placeholder and
DataModel.
Joins¶
Joins are used to establish relationships between placeholders. In order
to join two placeholders, the data frames used to derive them should both
have at least one join_key.
The joining itself is done
using the getml.data.Placeholder.join() method.
All
columns corresponding to time stamps have to be given the role
time_stamp and one of them in
both the population and peripheral table is usually passed to the
getml.data.Placeholder.join() method. This prevents easter eggs by
incorporating only those rows of the peripheral table in the join
operation for which the time stamp of the corresponding row in the
population table is either the same or more recent. This ensures that no
information from the future is considered during training.
Data schemata¶
After having created placeholders for all data frames in an analysis, we are ready to create the actual data schema. A data schema is a certain way of assembling population and peripheral tables.
The star schema¶
The StarSchema is the simplest way of
establishing relations between the
population and the peripheral tables. It is sufficient for the
majority of data science projects.
In the star schema, the population table is surrounded by any number of peripheral tables, all joined via a certain join key. However, no joins between peripheral tables are allowed.
Because this is a very popular schema in many machine learning
problems on relational data, getML contains a special class
for these sort of problems: StarSchema.
The population table and two peripheral tables introduced in Tables can be arranged in a star schema like this:
The snowflake schema¶
In some cases, the star schema is not enough to represent the complexity of a data set. This is where the snowflake schema comes in: In a snowflake schema, peripheral tables can have peripheral tables of their own.
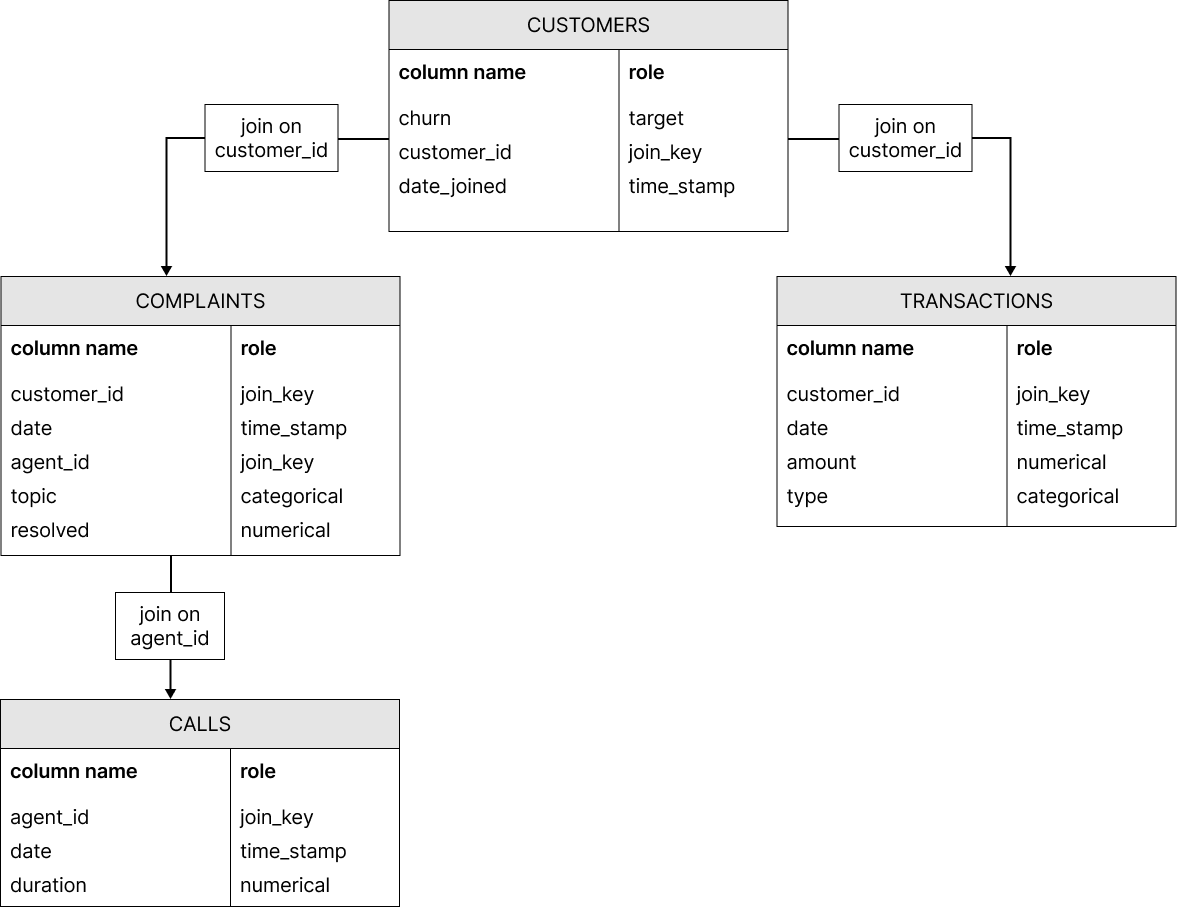
Assume that in the customer churn analysis shown above, there is an
additional table containing information about the calls a certain agent made in
customer service. It can be joined to the COMPLAINTS table using the
key agent_id.
In order to model snowflake schemata, you need to use the
DataModel and Container
classes.
Time series¶
Time series can be handled by a self join (self-joining a single table). In addition, some extra parameters and considerations are required when building features based on time stamps.
Self-joining a single table¶
If you deal with a classical (multivariate) time series and all your data is contained in a single table, all the concepts covered so far still apply. You just have to do a so-called self-join by providing your table as both population and peripheral table and join them.
You can think of the process as working in the following way: Whenever a row in the population table - a single measurement - is taken, it will be combined with all the content of the peripheral table - the same time series - for which the time stamps are smaller than the one in the line we picked.
You can also use
TimeSeries, which abstracts away
the self-join. In this case, you do not have think about self-joins
too much.
Features based on time stamps¶
The getML
engine is able to automatically generate features based on
aggregations over time windows. Both the length of the time window and
the aggregation itself will be figured out by the feature learning
algorithm. The only thing you have to do is to provide the temporal
resolution your time series is sampled with in the delta_t
parameter in any feature learning algorithm.