MultirelModel¶
-
class
getml.models.MultirelModel(population, peripheral, name='', feature_selector=None, predictor=None, units={}, session_name='', aggregation=['AVG', 'COUNT', 'MAX', 'MIN', 'SUM'], allow_sets=True, delta_t=0.0, grid_factor=1.0, include_categorical=False, loss_function=SquareLoss: type: SquareLoss, max_length=4, min_num_samples=1, num_features=100, num_subfeatures=100, num_threads=0, regularization=0.0, round_robin=False, sampling_factor=1.0, seed=None, send=False, share_aggregations=0.25, share_conditions=1.0, share_selected_features=0.0, shrinkage=0.0, silent=False, use_timestamps=True)¶ Bases:
objectFeature engineering based on Multi-Relational Decision Tree Learning.
MultirelModelautomates feature engineering for relational data and time series. It is based on an efficient variation of the Multi-Relational Decision Tree Learning (MRDTL) algorithm and uses the getML Multirel algorithm.For more information on the underlying feature engineering algorithm, check out the User guide. For details about the
MultirelModelcontainer in general, see the documentation of themodelsmodule.Examples
A
MultirelModelcan be created in two different ways. The first one is to directly use the constructor:population_table, peripheral_table = getml.datasets.make_numerical() population_placeholder = population_table.to_placeholder() peripheral_placeholder = peripheral_table.to_placeholder() population_placeholder.join(peripheral_placeholder, join_key="join_key", time_stamp="time_stamp" ) model = getml.models.MultirelModel( population=population_placeholder, peripheral=peripheral_placeholder, name="multirel", aggregation=[ getml.models.aggregations.Count, getml.models.aggregations.Sum ], predictor=getml.predictors.LinearRegression() )
This creates a handler in the Python API. To construct the actual model in the getML engine, the information in the handler has to be sent to the engine:
model.send()
You can also call the
MultirelModel()constructor with the send argument set to True.The second way of obtaining a
MultirelModelhandler to a model is to useload_model():model_loaded = getml.models.load_model("model-name")
- Parameters
population (
Placeholder) – Abstract representation of the main table.peripheral (Union[
Placeholder, List[Placeholder]]) – Abstract representations of the additional tables used to augment the information provided in population. These have to be the same objects that gotjoin()on the populationPlaceholderand their order strictly determines the order of the peripheralDataFrameprovided in the ‘peripheral_tables’ argument offit(),predict(),score(), andtransform().name (str, optional) – Unique name of the container created in the getML engine. If an empty string is provided, a random value based on the current time stamp will be used.
feature_selector (
predictors, optional) – Predictor used to selected the best features among all automatically generated ones.predictor (
predictors, optional) – Predictor used to make predictions on new, unseen data.units (dict, optional) – DEPRECATED: only required when a
pandas.DataFrameis provided in thefit(),predict(),score(), andtransform()method. If you already uploaded your data to the getML engine, this argument will not have any effect and can be omitted.session_name (string, optional) – Determines whether which
hyperoptrun the model was created in or - in case of an empty string - if it’s a stand-alone one.aggregation (List[
aggregations], optional) –Mathematical operations used by the automated feature engineering algorithm to create new features.
Possible options:
allow_sets (bool, optional) –
Multirel can summarize different categories into sets for producing conditions. When expressed as SQL statements these sets might look like this:
t2.category IN ( 'value_1', 'value_2', ... )
This can be very powerful, but it can also produce features that are hard to read and might be prone to overfitting when the sampling_factor is too low.
delta_t (float, optional) –
Frequency with which lag variables will be explored in a time series setting. When set to 0.0, there will be no lag variables.
Please note that getML does not handle UNIX time stamps, but encodes time as multiples and fractions of days since the 01.01.1970 (1970-01-01T00:00:00). For example
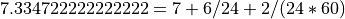 would be interpreted 1970-01-08T06:02:00.
would be interpreted 1970-01-08T06:02:00.For more information see Time series. Range: [0,
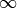 ]
]grid_factor (float, optional) – Multirel will try a grid of critical values for your numerical features. A higher grid_factor will lead to a larger number of critical values being considered. This can increase the training time, but also lead to more accurate features. Range: (0,
]include_categorical (bool, optional) – Whether you want to pass categorical columns from the population table to the feature_selector and predictor. Passing columns directly allows you to include handcrafted feature as well as raw data. Note, however, that this does not guarantee their presence in the resulting features because it is the task of the feature_selector to pick only the best performing ones.
loss_function (
loss_functions, optional) – Objective function used by the feature engineering algorithm to optimize your features. For regression problems useSquareLossand for classification problems useCrossEntropyLoss.max_length (int, optional) –
The maximum length a subcondition might have. Multirel will create conditions in the form
(condition 1.1 AND condition 1.2 AND condition 1.3 ) OR ( condition 2.1 AND condition 2.2 AND condition 2.3 ) ...
Using this parameter you can set the maximum number of conditions allowed in the brackets. Range: [0,
]min_num_samples (int, optional) – Determines the minimum number of samples a subcondition should apply to in order for it to be considered. Higher values lead to less complex statements and less danger of overfitting. Range: [1,
]num_features (int, optional) – Number of features generated by the feature engineering algorithm. For the total number of features available share_selected_features has to be taken into account as well. Range: [1,
]num_subfeatures (int, optional) – The number of subfeatures you would like to extract in a subensemble (for snowflake data model only). See The snowflake schema for more information. Range: [1,
]num_threads (int, optional) – Number of threads used by the feature engineering algorithm. If set to zero or a negative value, the number of threads will be determined automatically by the getML engine. Range: [-
, ]regularization (float, optional) – Most important regularization parameter for the quality of the features produced by Multirel. Higher values will lead to less complex features and less danger of overfitting. A regularization of 1.0 is very strong and allows no conditions. Range: [0, 1]
round_robin (bool, optional) – If True, the Multirel picks a different aggregation every time a new feature is generated.
sampling_factor (float, optional) – Multirel uses a bootstrapping procedure (sampling with replacement) to train each of the features. The sampling factor is proportional to the share of the samples randomly drawn from the population table every time Multirel generates a new feature. A lower sampling factor (but still greater than 0.0), will lead to less danger of overfitting, less complex statements and faster training. When set to 1.0, roughly 2,000 samples are drawn from the population table. If the population table contains less than 2,000 samples, it will use standard bagging. When set to 0.0, there will be no sampling at all. Range: [0,
]seed (Union[int,None], optional) – Seed used for the random number generator that underlies the sampling procedure to make the calculation reproducible. Due to nature of the underlying algorithm this is only the case if the fit is done without multithreading. To reflect this, a seed of None does represent an unreproducible and is only allowed to be set to an actual integer if both num_threads and
n_jobsinstance variables of the predictor and feature_selector - if they are instances of eitherXGBoostRegressororXGBoostClassifier- are set to 1. Internally, a seed of None will be mapped to 5543. Range: [0,]send (bool, optional) – If True, the Model will be automatically sent to the getML engine without you having to explicitly call
send().share_aggregations (float, optional) – Every time a new feature is generated, the aggregation will be taken from a random subsample of possible aggregations and values to be aggregated. This parameter determines the size of that subsample. Only relevant when round_robin is False. Range: (0, 1]
share_conditions (float, optional) – Every time a new column is tested for applying conditions, it might be skipped at random. This parameter determines the probability that a column will not be skipped. Range: [0, 1]
share_selected_features (float, optional) – Percentage of features selected by the feature_selector. Any feature with a importance of zero will be removed. Therefore, the number of features actually selected can be smaller than num_features * share_selected_features. When set to 0.0, no feature selection will be conducted and all generated ones will provided in
transform()and used inpredict(). Range: [0, 1]shrinkage (float, optional) – Since Multirel works using a gradient-boosting-like algorithm, shrinkage (or learning rate) scales down the weights and thus the impact of each new tree. This gives more room for future ones to improve the overall performance of the model in this greedy algorithm. Higher values will lead to more danger of overfitting. Range: [0, 1]
silent (bool, optional) – Controls the logging during training.
use_timestamps (bool, optional) –
Whether you want to ignore all elements in the peripheral tables where the time stamp is greater than the one in the corresponding elements of the population table. In other words, this determines whether you want add the condition
t2.time_stamp <= t1.time_stamp
at the very end of each feature. It is strongly recommend to enable this behavior.
Raises –
- TypeError:
If any of the input arguments is of wrong type.
- KeyError:
If an unsupported instance variable is encountered (via
validate()).- TypeError:
If any instance variable is of wrong type (via
validate()).- ValueError:
If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
Methods Summary
copy([new_name])Creates a copy of the model in the engine and returns its handler.
delete()Deletes the underlying model from the engine.
deploy(deploy)Allows a fitted model to be addressable via an HTTP(S) request.
fit(population_table, peripheral_tables)Trains the feature engineering algorithm and all predictors on the provided data.
predict(population_table, peripheral_tables)Forecasts on new, unseen data using the trained
predictor.refresh()Reloads the model from the engine.
score(population_table, peripheral_tables)Calculates the performance of the
predictor.send()Creates a model in the getML engine.
to_sql()Returns SQL statements visualizing the trained features.
transform(population_table, peripheral_tables)Translates new data into the trained features.
validate()Checks both the types and the values of all instance variables and raises an exception if something is off.
Methods Documentation
-
copy(new_name='')¶ Creates a copy of the model in the engine and returns its handler.
Since there can not be two models in the engine holding the same name, a new_name has to be assigned to the new one (which must not be present in the engine yet).
Examples
A possible use case is to pick a particularly well-performing model, create a new one based on it, do a slight adjustment of its attributes, and fit it.
model = getml.models.load_model("multirel") model_new = model.copy("model-new") model_new.regularization = 0.8 model_new.send() model_new.fit(population_table, peripheral_table)
- Parameters
new_name (str, optional) – Name of the new model. In case of an empty string, a new name will be generated automatically.
- Raises
NameError – If there is already a model present in the engine carrying the name new_name.
TypeError – If new_name is not of type str.
KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
The handler of the copied model.
- Return type
-
delete()¶ Deletes the underlying model from the engine.
- Raises
KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
Note
Caution: You can not undo this action!
-
deploy(deploy)¶ Allows a fitted model to be addressable via an HTTP(S) request. See Deployment for details.
- Parameters
deploy (bool) – If
True, the deployment of the model will be triggered.- Raises
TypeError – If deploy is not of type bool.
KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
-
fit(population_table, peripheral_tables)¶ Trains the feature engineering algorithm and all predictors on the provided data.
Both the
feature_selectorandpredictorwill be trained alongside the Multirel feature engineering algorithm if present.Examples
model.fit( population_table = population_table, peripheral_tables = peripheral_table)
- Parameters
population_table (Union[
pandas.DataFrame,getml.data.DataFrame]) – Main table containing the target variable(s) and corresponding to thepopulationPlaceholderinstance variable.peripheral_tables (Union[
pandas.DataFrame,getml.data.DataFrame, List[pandas.DataFrame],List[getml.data.DataFrame]]) – Additional tables corresponding to theperipheralPlaceholderinstance variable. They have to be provided in the exact same order as their corresponding placeholders! A single DataFrame will be wrapped into a list internally.
- Raises
IOError – If the model corresponding to the instance variable
namecould not be found on the engine or the model could not be fitted.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
Note
This method will only work if there is a corresponding model in the getML engine. If you used the
MultirelModelconstructor of the model in the Python API, be sure to use thesend()method afterwards create its counterpart in the engine.All parameters customizing this process have been already supplied to the constructor and are assigned as instance variables. Any changes applied to them will only be respected if the
send()method will be called on the modified version of the model first.If a population_table or peripheral_tables will be provided as
pandas.DataFrame, they will be converted to temporarygetml.data.DataFrame, uploaded to the engine, and discarded after the function call. Since peripheral_tables can very well be the same for thepredict(),score(), andtransform()methods, this way of interacting with the engine can be highly inefficient and is discouraged.
-
predict(population_table, peripheral_tables, table_name='')¶ Forecasts on new, unseen data using the trained
predictor.Returns the predictions generated by the model based on population_table and peripheral_tables or writes them into a data base named table_name.
Examples
model.predict( population_table = population_table, peripheral_tables = peripheral_table)
- Parameters
population_table (Union[
pandas.DataFrame,getml.data.DataFrame]) – Main table corresponding to thepopulationPlaceholderinstance variable. Its target variable(s) will be ignored.peripheral_tables (Union[
pandas.DataFrame,getml.data.DataFrame, List[pandas.DataFrame],List[getml.data.DataFrame]]) – Additional tables corresponding to theperipheralPlaceholderinstance variable. They have to be provided in the exact same order as their corresponding placeholders! A single DataFrame will be wrapped into a list internally.table_name (str, optional) – If not an empty string, the resulting predictions will be written into the
databaseof the same name. See Unified import interface for further information.
- Raises
IOError – If the model corresponding to the instance variable
namecould not be found on the engine or the model could not be fitted.TypeError – If any input argument is not of proper type.
ValueError – If no valid
predictorwas set/is None.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
Resulting predictions provided in an array of the (number of rows in population_table, number of targets in population_table).
- Return type
numpy.ndarray
Note
Only fitted models (
fit()) can be used for prediction. In addition, a validpredictormust be trained as well.If a population_table or peripheral_tables will be provided as
pandas.DataFrame, they will be converted to temporarygetml.data.DataFrame, uploaded to the engine, and discarded after the function call. Since peripheral_tables can very well be the same for thepredict(),score(), andtransform()methods, this way of interacting with the engine can be highly inefficient and is discouraged.
-
refresh()¶ Reloads the model from the engine.
Discards all local changes applied to the model after the last invocation of its
send()method by loading the model corresponding to thenameattribute from the engine and replacing the attributes of the current instance with the results.- Raises
IOError – If the engine did not send a proper model.
- Returns
Current instance
- Return type
-
score(population_table, peripheral_tables)¶ Calculates the performance of the
predictor.Returns different scores calculated on population_table and peripheral_tables.
Examples
model.score( population_table = population_table, peripheral_tables = peripheral_table)
- Parameters
population_table (Union[
pandas.DataFrame,getml.data.DataFrame]) – Main table corresponding to thepopulationPlaceholderinstance variable. Its target variable(s) will be ignored.peripheral_tables (Union[
pandas.DataFrame,getml.data.DataFrame, List[pandas.DataFrame],List[getml.data.DataFrame]]) – Additional tables corresponding to theperipheralPlaceholderinstance variable. They have to be provided in the exact same order as their corresponding placeholders! A single DataFrame will be wrapped into a list internally.
- Raises
IOError – If the model corresponding to the instance variable
namecould not be found on the engine or the model could not be fitted.TypeError – If any input argument is not of proper type.
ValueError – If no valid
predictorwas set/is None.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
Mapping of the name of the score (str) to the corresponding value (float).
For regression problems the following scores are returned:
For classification problems, on the other hand, the following scores are returned: Possible values for a classification problem are:
- Return type
dict
Note
Only fitted models (
fit()) can be scored. In addition, a validpredictormust be trained as well.If a population_table or peripheral_tables will be provided as
pandas.DataFrame, they will be converted to temporarygetml.data.DataFrame, uploaded to the engine, and discarded after the function call. Since peripheral_tables can very well be the same for thepredict(),score(), andtransform()methods, this way of interacting with the engine can be highly inefficient and is discouraged.
-
send()¶ Creates a model in the getML engine.
Serializes the handler with all information provided either via the
__init__()method, byload_model(), or by manually altering the instance variables. These will be sent to the engine, which constructs a new model based on them.- Raises
TypeError – If the population instance variables is not of type
Placeholderand peripheral is not a list of these.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
Current instance
- Return type
Note
If there is already a model with the same
nameattribute is present in the getML engine, it will be replaced. Therefore, when calling thesend()method afterfit()all fit results (and calculated scores) will be discarded too and the model has to be refitted.Imagine you run the following command
model.fit( population_table = population_table, peripheral_tables = peripheral_table) model.send()
Is it possible to undo the changes resulting from calling
send()?The discarding of the old model just happens in memory since the
send()does not trigger the_save()method and thus does not write the new model to disk. These in-memory changes can be undone by usingset_project()to switch to a different project and right back to the current one. Since the loading of a project is accomplished by reading all corresponding objects written to disk, we have restored the fitted model.
-
to_sql()¶ Returns SQL statements visualizing the trained features.
In order to get insight into the complex features, they are expressed as SQL statements.
Examples
print(model.to_sql())
- Raises
IOError – If the model corresponding to the instance variable
namecould not be found on the engine or the model could not be fitted.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
String containing the formatted SQL command.
- Return type
str
Note
Only fitted models (
fit()) do hold trained features which can be returned as SQL statements.In order to display the returned string properly, it has to be pretty printed first using the
print()function.The dialect is based on SQLite3 but not guaranteed to be fully compliant with its standard.
-
transform(population_table, peripheral_tables, df_name='', table_name='')¶ Translates new data into the trained features.
Transforms the data provided in population_table and peripheral_tables into features, which can be used to drive machine learning models. In addition to returning them as numerical array, this method is also able to write the results in a data base called table_name.
Examples
model.transform( population_table = population_table, peripheral_tables = peripheral_table)
- Parameters
population_table (Union[
pandas.DataFrame,getml.data.DataFrame]) – Main table corresponding to thepopulationPlaceholderinstance variable. Its target variable(s) will be ignored.peripheral_tables (Union[
pandas.DataFrame,getml.data.DataFrame, List[pandas.DataFrame],List[getml.data.DataFrame]]) – Additional tables corresponding to theperipheralPlaceholderinstance variable. They have to be provided in the exact same order as their corresponding placeholders! A single DataFrame will be wrapped into a list internally.df_name (str, optional) – If not an empty string, the resulting features will be written into a newly created DataFrame.
table_name (str, optional) – If not an empty string, the resulting features will be written into the
databaseof the same name. See Unified import interface for further information.
- Raises
IOError – If the model corresponding to the instance variable
namecould not be found on the engine or the model could not be fitted.TypeError – If any input argument is not of proper type.
KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
- Returns
- Resulting features provided in an array of the
(number of rows in population_table, number of selected features).
- or
getml.data.DataFrame: A DataFrame containing the resulting features.
- Return type
numpy.ndarray
Note
Only fitted models (
fit()) can transform data into features.If a population_table or peripheral_tables will be provided as
pandas.DataFrame, they will be converted to temporarygetml.data.DataFrame, uploaded to the engine, and discarded after the function call. Since peripheral_tables can very well be the same for thepredict(),score(), andtransform()methods, this way of interacting with the engine can be highly inefficient and is discouraged.
-
validate()¶ Checks both the types and the values of all instance variables and raises an exception if something is off.
Examples
population_table, peripheral_table = getml.datasets.make_numerical() population_placeholder = population_table.to_placeholder() peripheral_placeholder = peripheral_table.to_placeholder() population_placeholder.join(peripheral_placeholder, join_key = "join_key", time_stamp = "time_stamp" ) model = getml.models.MultirelModel( population = population_placeholder, peripheral = peripheral_placeholder, name = "multirel" ) model.num_features = 300 model.shrinkage = 1.7 model.validate()
- Raises
KeyError – If an unsupported instance variable is encountered.
TypeError – If any instance variable is of wrong type.
ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical).
Note
This method is triggered at end of the __init__ constructor and every time a function communicating with the getML engine - except
refresh()- is called.To directly access the validity of single or multiple parameters instead of the whole class, you can used
getml.helpers.validation.validate_MultirelModel_parameters().