Deployment¶
The results of both the feature engineering and the prediction are provided in different ways and formats by the getML suite.
Returning Python objects
Using the
transform()andpredict()methods of a trainedMultirelModelorRelboostModelyou can access both the features and the predictions asnumpy.ndarrayvia the Python API.
Writing into a database
You can also write both features and prediction results back into a new table of the connected database by providing the
table_nameargument in thetransform()andpredict()methods. Please refer to the unified import interface for how to connect a database.
Responding to a HTTP(S) POST request
The getML suite also offers per model HTTP(S) endpoints you can post new data to via a JSON string and retrieve either the resulting features or the predictions. The remainder of this chapter covers how this is done in detail.
Prerequisites¶
But first of all, let’s begin with an example model we can illustrate the working of the endpoints with.
import getml
# Setting up the engine.
getml.engine.set_project("deployment")
# Generate some random data.
population_data_frame, peripheral_data_frame = getml.datasets.make_numerical(
random_state=2222,
population_name="population_table",
peripheral_name="peripheral_table"
)
# Building the data model.
population_placeholder = population_data_frame.to_placeholder()
peripheral_placeholder = peripheral_data_frame.to_placeholder()
population_placeholder.join(peripheral_placeholder, "join_key", "time_stamp")
# Construct the feature engineering and prediction pipeline.
predictor = getml.predictors.LinearRegression()
model = getml.models.MultirelModel(
name="MyModel",
aggregation=[
getml.models.aggregations.Count,
getml.models.aggregations.Sum
],
population=population_placeholder,
peripheral=[peripheral_placeholder],
loss_function=getml.models.loss_functions.SquareLoss(),
predictor=predictor,
num_features=10,
share_aggregations=1.0,
max_length=1,
seed=2222
).send()
# Train both the feature engineering algorithm and the machine
# learning routines used for prediction.
model.fit(
population_table=population_data_frame,
peripheral_tables=peripheral_data_frame
)
# Tell the getML monitor to whitelist the particular model for access
# via HTTP(S).
model.deploy(True)
Both the data model and the data itself are quite similar to what has been used during the getting started guide and their overall structure look like this
print(population_data_frame)
| time_stamp | join_key | targets | column_01 |
| time stamp | join key | target | numerical |
-----------------------------------------------------------------
| 1970-01-01T05:33:24.789405Z | 0 | 54 | 0.4544 |
| 1970-01-01T20:37:18.369208Z | 1 | 151 | -0.422029 |
| ... | ... | ... | ... |
and
print(peripheral_data_frame)
| time_stamp | join_key | column_01 |
| time stamp | join key | numerical |
------------------------------------------------------
| 1970-01-01T02:16:34.823342Z | 397 | 0.938692 |
| 1970-01-01T04:35:12.660807Z | 146 | -0.378773 |
| ... | ... | ... |
Please note the call to the
deploy() method of our trained
model. Per default the getML monitor does disable the feature
engineering and prediction endpoints of each model and one has to
explicitly whitelist them.
HTTP(S) Endpoints¶
As soon as you have trained a model,
whitelisted it for external access using its
deploy() method, and configured
the getML monitor for remote access, you can
both transform new data into features or make predictions on them
using these endpoints
transform endpoint: https://route-to-your-monitor:1710/transform/MODEL_NAME
predict endpoint: https://route-to-your-monitor:1710/predict/MODEL_NAME
To each of them you have to send a POST request containing the new data as a JSON string in a specific request format.
Note
For testing and developing purposes you can also use the HTTP port of the monitor to query the endpoints. Note, however, that this is only possible within the same host. The corresponding syntax is http://localhost:1709/predict/MODEL_NAME
Request Format¶
In all POST requests to the endpoints a JSON string with the following syntax has to be provided in the body
{
"peripheral": [{
"column_1": [],
"column_2": []
},{
"column_1": [],
"column_2": []
}],
"population": {
"column_1": [],
"column_2": []
}
}
It has to have exactly two keys in the top level called
population and peripheral. These will contain the new
input data. Their naming is independent of the names of both the
DataFrame and Placeholder
objects you put into the constructor or the training of your
model.
The order of the top-level keys as well as the order of the column
names is irrelevant. They will be matched according to their
names. Note however that, on the other hand, the order of the
individual peripheral tables is very important and has to exactly
match the order the corresponding Placeholder
have been provided in the constructor of model.
Coming back to our example above, we will just provide two new points for the main table (for the sake of brevity) and a couple new ones for our single peripheral table.
{
"peripheral": [{
"column_01": [2.4, 3.0, 1.2, 1.4, 2.2],
"join_key": ["0", "0", "0", "0", "0"],
"time_stamp": [0.1, 0.2, 0.3, 0.4, 0.8]
}],
"population": {
"column_01": [2.2, 3.2],
"join_key": ["0", "0"],
"time_stamp": [0.65, 0.81]
}
}
Time stamp formats in requests¶
You might noticed that the time stamps in the example above have been provided as numerical values and not as their string representations shown in the beginning. Both ways are supported by the getML monitor. But if you choose to provide the string representation, you also have to specify the particular format in order for the getML engine to interpret your data properly.
{
"peripheral": [{
"column_01": [2.4, 3.0, 1.2, 1.4, 2.2],
"join_key": ["0", "0", "0", "0", "0"],
"time_stamp": ["2010-01-01 00:15:00", "2010-01-01 08:00:00", "2010-01-01 09:30:00", "2010-01-01 13:00:00", "2010-01-01 23:35:00"]
}],
"population": {
"column_01": [2.2, 3.2],
"join_key": ["0", "0"],
"time_stamp": ["2010-01-01 12:30:00", "2010-01-01 23:30:00"]
},
"timeFormats": ["%Y-%m-%d %H:%M:%S"]
}
All special characters available for specifying the format of the time
stamps are listed and described in
e.g. getml.data.DataFrame.read_csv().
Please note that getML does not handle UNIX time stamps but,
instead, encodes time as multiples and fractions of days since the
01.01.1970 (1970-01-01T00:00:00). For example
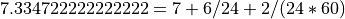 would be interpreted
1970-01-08T06:02:00.
would be interpreted
1970-01-08T06:02:00.
Using an existing DataFrame¶
In your relational data model the peripheral
tables might stay the same for every new
observation you want to pipe through your deployed model. Instead of
uploading them in each new POST request, you can use a
DataFrame already existing in the getML engine
via the df key in combination with the name of the
corresponding table as its value.
{
"peripheral": [{
"df": "peripheral_table"
}],
"population": {
"column_01": [2.2, 3.2],
"join_key": ["0", "0"],
"time_stamp": [0.65, 0.81]
}
}
Using data from a database¶
You can also read the peripheral tables from the connected database
(see unified import interface) using
an arbitrary query via the query key.
{
"peripheral": [{
"query": "SELECT * FROM 'PERIPHERAL' WHERE 'join_key' = '0';"
}],
"population": {
"column_01": [2.2, 3.2],
"join_key": ["0", "0"],
"time_stamp": [0.65, 0.81]
}
}
Transform Endpoint¶
To harness the power of automated feature engineering using getML but still operate on your well established machine learning pipelines, you can use the transform endpoint. Using a POST request you can upload new, unseen data via the getML monitor into the engine, transform it into a flat feature table using the trained feature engineering routines, and receive the corresponding flat feature table as response via HTTP(S).
https://route-to-your-monitor:1710/transform/MODEL_NAME
Such an HTTP(S) request can be send in many languages. For
illustration purposes we will use the command line tool curl,
which comes preinstalled on both Linux and macOS. Also, we will use
the HTTP port via localhost (only possible for terminals running on
the same machine as the getML monitor) for better reproducibility.
curl --header "Content-Type: application/json" \
--request POST \
--data '{"peripheral":[{"column_01":[2.4,3.0,1.2,1.4,2.2],"join_key":["0","0","0","0","0"],"time_stamp":[0.1,0.2,0.3,0.4,0.8]}],"population":{"column_01":[2.2,3.2],"join_key":["0","0"],"time_stamp":[0.65,0.81]}}' \
http://localhost:1709/transform/MyModel
Predict Endpoint¶
When using getML as an end-to-end data science pipeline, you can use the predict endpoint to upload new, unseen data and receive the resulting predictions as response via HTTP(S).
https://route-to-your-monitor:1710/predict/MODEL_NAME
Such an HTTP(S) request can be send in many languages. For
illustration purposes we will use the command line tool curl,
which comes preinstalled on both Linux and macOS. Also, we will use
the HTTP port via localhost (only possible for terminals running on
the same machine as the getML monitor) for better reproducibility.
curl --header "Content-Type: application/json" \
--request POST \
--data '{"peripheral":[{"column_01":[2.4,3.0,1.2,1.4,2.2],"join_key":["0","0","0","0","0"],"time_stamp":[0.1,0.2,0.3,0.4,0.8]}],"population":{"column_01":[2.2,3.2],"join_key":["0","0"],"time_stamp":[0.65,0.81]}}' \
http://localhost:1709/predict/MyModel