LatinHypercubeSearch¶
-
class
getml.hyperopt.LatinHypercubeSearch(param_space, pipeline, score='rmse', n_iter=100, seed=5483, **kwargs)¶ Bases:
getml.hyperopt.hyperopt._HyperoptLatin hypercube sampling of the hyperparameters.
Uses a multidimensional, uniform cumulative distribution function to drawn the random numbers from. For drawing n_iter samples, the distribution will be divided in n_iter`*`n_iter hypercubes of equal size (n_iter per dimension). n_iter of them will be selected in such a way only one per dimension is used and an independent and identically-distributed (iid) random number is drawn within the boundaries of the hypercube.
A latin hypercube search can be seen as a compromise between a grid search, which iterates through the entire hyperparameter space, and a random search, which draws completely random samples from the hyperparameter space.
- Parameters
param_space (dict) –
Dictionary containing numerical arrays of length two holding the lower and upper bounds of all parameters which will be altered in pipeline during the hyperparameter optimization.
If we have two feature learners and one predictor, the hyperparameter space might look like this:
param_space = { "feature_learners": [ { "num_features": [10, 50], }, { "max_depth": [1, 10], "min_num_samples": [100, 500], "num_features": [10, 50], "reg_lambda": [0.0, 0.1], "shrinkage": [0.01, 0.4] }], "predictors": [ { "reg_lambda": [0.0, 10.0] } ] }
If we only want to optimize the predictor, then we can leave out the feature learners.
pipeline (
Pipeline) – Base pipeline used to derive all models fitted and scored during the hyperparameter optimization. Be careful in constructing it since only those parameters present in param_space will be overwritten. It defines the data schema and any hyperparameters that are not optimized.score (str, optional) – The score to optimize. Must be from
scores.n_iter (int, optional) – Number of iterations in the hyperparameter optimization and thus the number of parameter combinations to draw and evaluate. Range: [1,
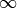 ]
]seed (int, optional) – Seed used for the random number generator that underlies the sampling procedure to make the calculation reproducible. Due to nature of the underlying algorithm this is only the case if the fit is done without multithreading. To reflect this, a seed of None represents an unreproducible and is only allowed to be set to an actual integer if both
num_threadsandn_jobsinstance variables of thepredictorandfeature_selectorin model - if they are instances of eitherXGBoostRegressororXGBoostClassifier- are set to 1. Internally, a seed of None will be mapped to 5543. Range: [0,]
- Raises
KeyError – If an unsupported instance variable is encountered.
TypeError – If any instance variable is of wrong type.
ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical).
ValueError – If no
predictoris present in the providedpipeline.
Example
from getml import data from getml import datasets from getml import engine from getml import feature_learning from getml.feature_learning import aggregations from getml.feature_learning import loss_functions from getml import hyperopt from getml import pipeline from getml import predictors # ---------------- engine.set_project("examples") # ---------------- population_table, peripheral_table = datasets.make_numerical() # ---------------- # Construct placeholders population_placeholder = data.Placeholder("POPULATION") peripheral_placeholder = data.Placeholder("PERIPHERAL") population_placeholder.join(peripheral_placeholder, "join_key", "time_stamp") # ---------------- # Base model - any parameters not included # in param_space will be taken from this. fe1 = feature_learning.MultirelModel( aggregation=[ aggregations.Count, aggregations.Sum ], loss_function=loss_functions.SquareLoss, num_features=10, share_aggregations=1.0, max_length=1, num_threads=0 ) # ---------------- # Base model - any parameters not included # in param_space will be taken from this. fe2 = feature_learning.RelboostModel( loss_function=loss_functions.SquareLoss, num_features=10 ) # ---------------- # Base model - any parameters not included # in param_space will be taken from this. predictor = predictors.LinearRegression() # ---------------- pipe = pipeline.Pipeline( population=population_placeholder, peripheral=[peripheral_placeholder], feature_learners=[fe1, fe2], predictors=[predictor] ) # ---------------- # Build a hyperparameter space. # We have two feature learners and one # predictor, so this is how we must # construct our hyperparameter space. # If we only wanted to optimize the predictor, # we could just leave out the feature_learners. param_space = { "feature_learners": [ { "num_features": [10, 50], }, { "max_depth": [1, 10], "min_num_samples": [100, 500], "num_features": [10, 50], "reg_lambda": [0.0, 0.1], "shrinkage": [0.01, 0.4] }], "predictors": [ { "reg_lambda": [0.0, 10.0] } ] } # ---------------- # Wrap a LatinHypercubeSearch around the reference model latin_search = hyperopt.LatinHypercubeSearch( pipeline=pipe, param_space=param_space, n_iter=30, score=pipeline.scores.rsquared ) latin_search.fit( population_table_training=population_table, population_table_validation=population_table, peripheral_tables=[peripheral_table] )
Attributes Summary
The best pipeline that is part of the hyperparameter optimization.
Name of the hyperparameter optimization.
Returns the ID of the hyperparameter optimization.
The score to be optimized.
The algorithm used for the hyperparameter optimization.
Methods Summary
fit(population_table_training, …[, …])Launches the hyperparameter optimization.
refresh()Reloads the hyperparameter optimization from the engine.
validate()Validate the parameters of the hyperparameter optimization.
Attributes Documentation
-
best_pipeline¶ The best pipeline that is part of the hyperparameter optimization.
This is always based on the validation data you have passed even if you have chosen to score the pipeline on other data afterwards.
-
id¶ Name of the hyperparameter optimization. This is used to uniquely identify it on the engine.
-
name¶ Returns the ID of the hyperparameter optimization. The name property is kept for backward compatibility.
-
score¶ The score to be optimized.
-
type¶ The algorithm used for the hyperparameter optimization.
Methods Documentation
-
fit(population_table_training, population_table_validation, peripheral_tables=None)¶ Launches the hyperparameter optimization.
The provided
DataFramepopulation_table_training, population_table_validation and peripheral_tables must be consistent with thePlaceholdersprovided when constructing the base model.- Parameters
population_table_training (
DataFrame) – The population table that pipelines will be trained on.population_table_validation (
DataFrame) – The population table that pipelines will be evaluated on.peripheral_tables (
DataFrame) – The peripheral tables used to provide additional information for the population tables.
- Raises
TypeError – If any of population_table_training, population_table_validation or peripheral_tables is not of type
DataFrame.KeyError – If an unsupported instance variable is encountered (via
validate()).TypeError – If any instance variable is of wrong type (via
validate()).ValueError – If any instance variable does not match its possible choices (string) or is out of the expected bounds (numerical) (via
validate()).
-
refresh()¶ Reloads the hyperparameter optimization from the engine.
- Raises
IOError – If the engine did not send a proper model.
- Returns
Current instance
- Return type
-
validate()¶ Validate the parameters of the hyperparameter optimization.